

AI Summarize
![]()
![]()
![]()
![]()
![]()
Share
![]()
![]()
![]()
Web scraping is all about acquiring information from somebody else's website. Many companies use third-party services that use various web scraping tools to build databases. These third parties then sell the data they've gathered to those who need various data sets.
Legal issues have developed around web scraping because some businesses don't appreciate having their data scraped. Owners of businesses that have been scraped worry about things like copyright infringement, fraud, breach of contract, trade secrets being stolen, and more.
In the following article, we'll take a look at web scraping laws, why they're important, and how your website's Terms and Conditions agreement (T&C) (also known as Terms of Service or Terms of Use) can limit the web scraping activity of others.
Our Terms and Conditions Generator makes it easy to create a Terms and Conditions agreement for your business. Just follow these steps:
-
At Step 1, select the Website option or the App option or both.
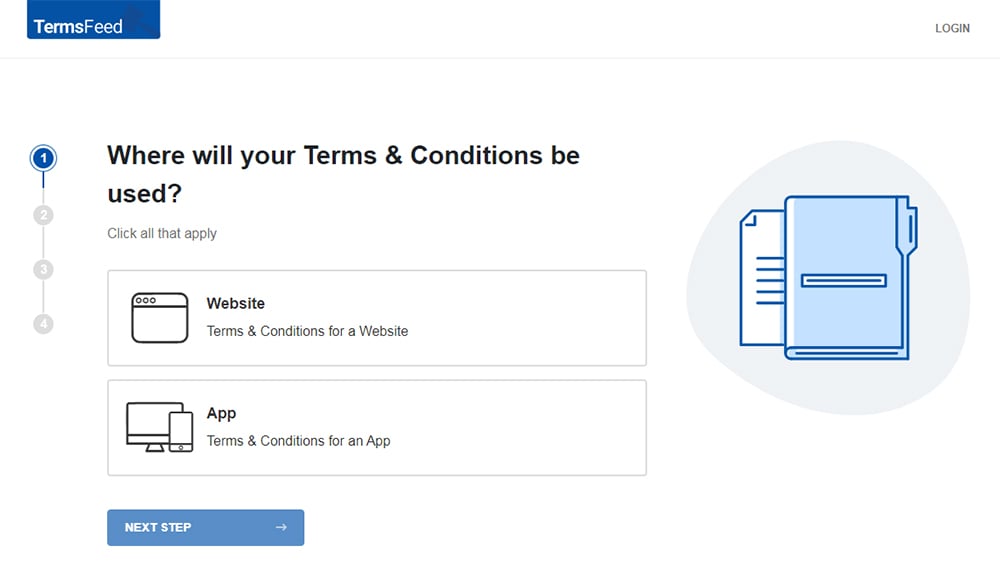
-
Answer some questions about your website or app.
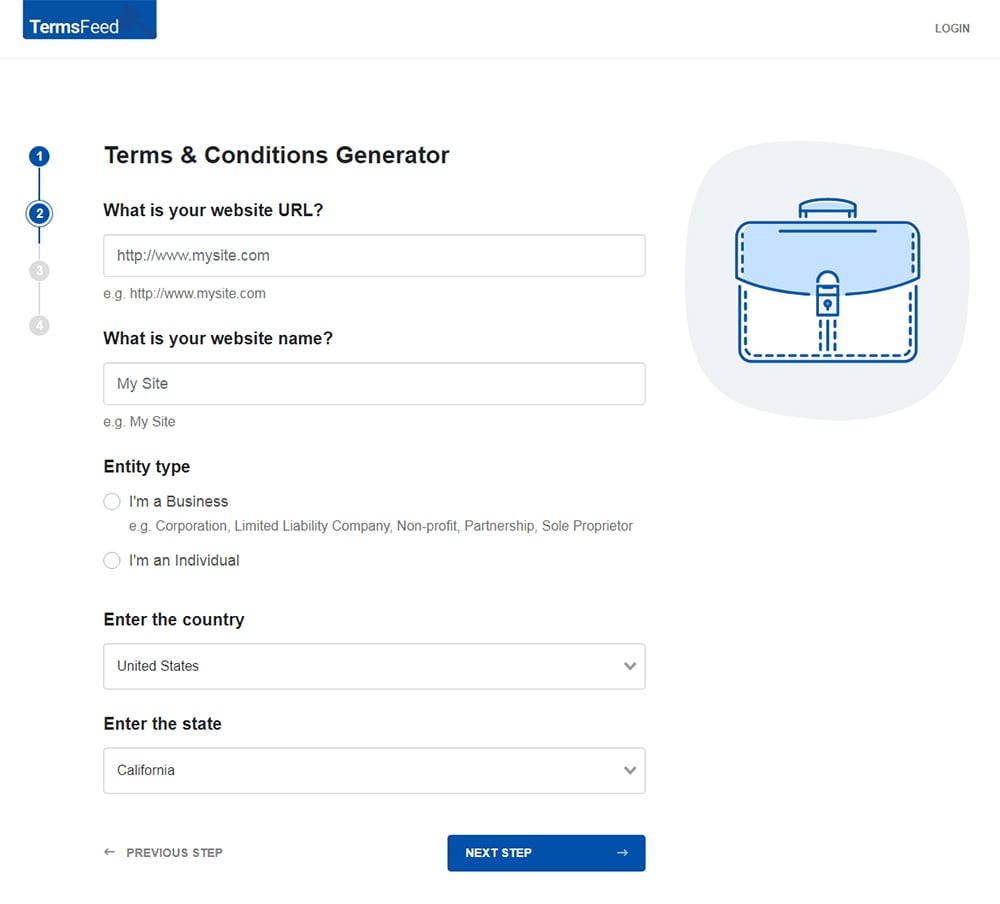
-
Answer some questions about your business.
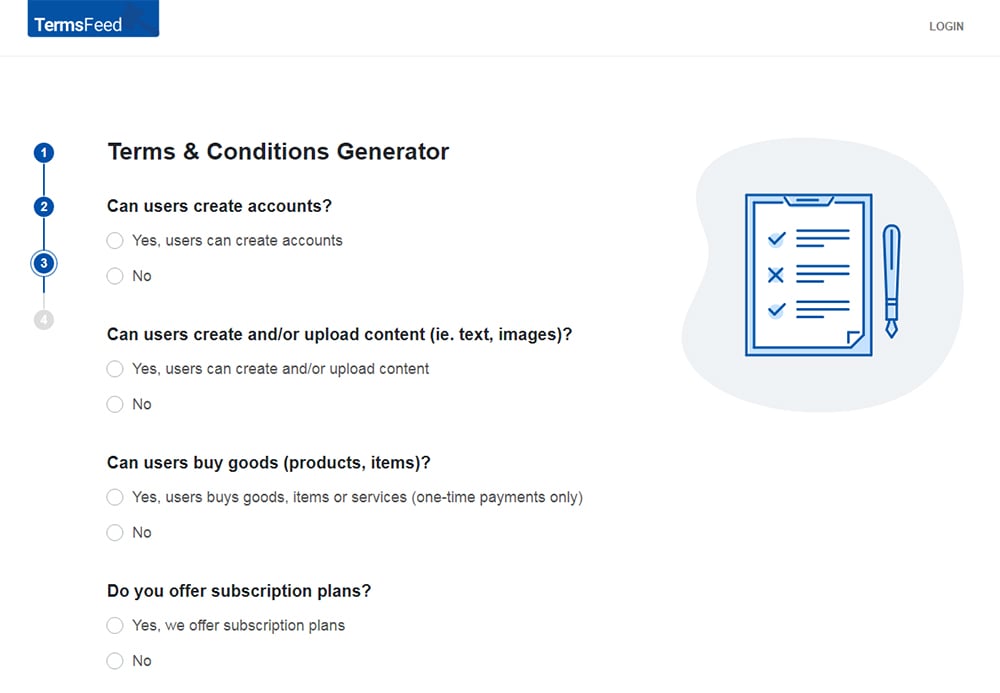
-
Enter the email address where you'd like the T&C delivered and click "Generate."
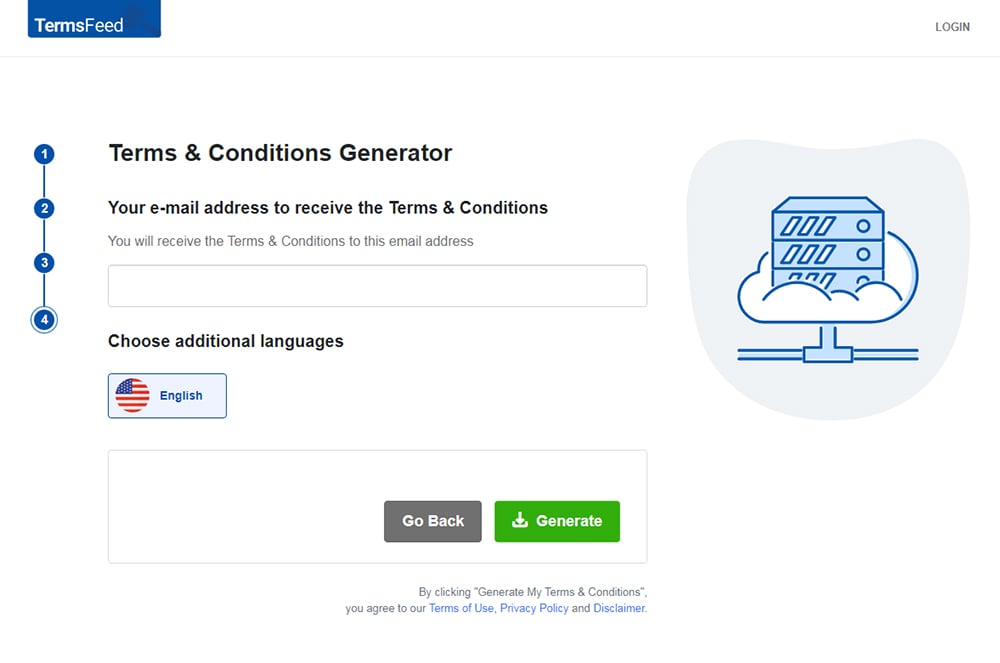
You'll be able to instantly access and download the Terms & Conditions agreement.




- 1. Is Web Scraping Legal?
- 2. Personal Data and Web Scraping: Why it Can Be Illegal
- 2.1. The GDPR
- 2.2. The CCPA
- 3. What to do if You Engage in Web Scraping
- 3.1. Be Mindful of Personal Data
- 3.2. Be Mindful of Copyrighted Data
- 3.3. Add Web Scraping Limits to Your Terms and Conditions Agreement
- 4. Other Concerns
- 5. Closing Thoughts
Is Web Scraping Legal?
The short answer is that the entire subject is a little gray. Up until 2015, companies were getting away with crawling their competitor's sites without a hitch. However, then the Irish airline Ryanaire went to court over alleged "screen-scraping" of its website.
In fact, the issue went all the way to the Court of Justice of the European Union (CJEU), Europe's highest court.
Essentially, what happened is that PR Aviation, a company that does price comparisons for low-cost airlines, and that depends on data acquired through screen-scraping information, which is publicly available, was accused of scraping Ryanair's website.
The airline sued PR Aviation for breach of its website T&C and for infringement of its database rights under the Database Directive. Further, Ryanair sought for PR Aviation to pay damages and to have the court order PR Aviation to cease and desist from further infringement.
In the end, the CJEU ruled in Ryanair's favor. Now, the airline could legally limit what can and cannot be scraped from its website through its Terms of Use Agreement. See Ryanair's exact wording for their web scraping restrictions below:

It says:
3. Permitted use.
You are not permitted to use this website (including the mobile app and any webpage and/or data that passes through the web domain at ryanair.com), its underlying computer programs (including application programming interfaces ("APIs")), domain names, Uniform Resource Locators ("URLs"), databases, functions or its content other than for private, non-commercial purposes. Use of any automated system or software, whether operated by a third party or otherwise, to extract any data from this website for commercial purposes ("screen scraping") is strictly prohibited.
Fast forward to 2020. The U.S. 9th Circuit Court of Appeals ruled on September 9 that the U.S.'s Computer Fraud and Abuse Act (CFAA) is not violated when a company scrapes public websites.
In other words, while there may be some limits in some regions that can be placed on scraping activity through a company's T&C Agreement, the U.S. court essentially ruled that it's not "theft" if a company scrapes information such as, product lots,open user profiles, ticket prices, etc.
The reason for this is that the scraper bot isn't any different from a legal standpoint than your web browser. Both request open data from the website, and both do something with that data on their side. As long as the data is publicly available on the site (i.e., you can see the data when browsing the site) then it's legal to scrape it.
Personal Data and Web Scraping: Why it Can Be Illegal
Otherwise known as Personally Identifiable Information (PII), this is a subject that's now covered in-depth by many data privacy and protection laws including Europe's General Data Protection Regulation (GDPR) as well as those of many states across America.
PII includes any information, which might be used to identify a specific individual. Examples of this type of information include:
- Name
- Address
- Date of birth
- Contact information
- Employment information
- Sexual preference
- Ethnicity
- Medical information and
- Financial information
Under most laws, PII is illegal to collect, use, or store without the owner's explicit consent. (Sometimes there are legal exceptions.)
When it comes to web scraping, you won't be able to obtain an owner's consent for collecting their data. Therefore, it's now a best practice to ensure that when scraping a website, you leave PII alone.
Different regions have a few different rules. Let's take a look at them.
The GDPR
The GDPR became enforceable in 2018 and it applies to the use of PII of residents within the European Economic Area (EEA).
Essentially, the important thing to keep in mind is that the GDPR has regulations covering the protection of PII when it is acquired by data controllers and then passed to data processors. (This includes the cloud.)
All companies, no matter where they are located in the world, are subject to the GDPR if they collect the PII of EEA residents. There are no exceptions.
You cannot legally scrape the websites of companies in the EEA for PII without first obtaining explicit consent to do so from the people whose data you'll be collecting. You can see how this would likely be impossible to do.
You can scrape data of EEA residents without consent if you have a valid lawful purpose, such as to complete a contract, or to satisfy a legal obligation.
The CCPA
California's Consumer Privacy Act (CCPA/CPRA) is modeled after the GDPR in a variety of ways, including the way personal information (personal data) is to be used legally.
If you plan to scrape a website for data, you will be violating the CCPA/CPRA if you collect personal data from residents of the state of California along the way without first obtaining consent or having a valid purpose under the law.
What to do if You Engage in Web Scraping
Here are some general best practices and principles to follow if you engage in web scraping and don't want to end up violating people's privacy rights and privacy laws.
Be Mindful of Personal Data
As noted above, don't scrape any personal data that can be used to identify an individual. You will be in direct violation of privacy laws that protect this sort of information from being collected and used without meeting specific legal requirements that likely aren't met when simply scraping or stealing information from a web page.
Just don't do it.
Be Mindful of Copyrighted Data
Copyrighted data is owned by businesses or individuals who have full control over its use and reproduction. This type of data may include:
- Images
- Databases
- Songs
- Articles, and
- Books
Just because this type of information may be easily available online, it doesn't mean that it is free for anyone to use. In fact, if it's copyrighted then it's illegal to use without the express permission of the owner.
What this means is that while it isn't illegal for you to scrape and gather copyrighted material per se, if you use that information, it certainly might be. Remember that specific laws in various countries are not entirely the same on this issue.
For example, in some places you may be able to use parts of the copyrighted data you've scraped, while in others you won't be able to use any of it at all.
Add Web Scraping Limits to Your Terms and Conditions Agreement
Despite some obvious limitations, you might still want to add web scraping restrictions to your website's T&C. When you do, make sure that your language is specific so that you can prohibit any third party from scraping your website's information and then using it for their own commercial purposes.
For example, most Terms agreements have a clause that addresses restricted uses and behaviors, like this:

This clause would be a great place to note that you don't allow web scraping and will consider it a violation of your terms.
Also, you'll need to ensure that your T&C is actually enforceable. Terms are normally enforceable when both parties agree to them. However, different courts use various criteria when determining if an agreement in reality exists.
For example, some courts may decide that when a user is merely notified that using a website constitutes an agreement to its terms, is enough. (This is usually done through a "browsewrap" agreement.) However, many agree that you'll have a stronger case if you use a "clickwrap" agreement that requires your site's users to explicitly agree to your T&C before continuing on to use the website.
To be safe, awlays request explicit consent via a checkbox or Agree type of button, like this:

Note that the Terms agreement is linked to the place where consent is requested.This helps make sure the user has ample opportunity to read and review the Terms before agreeing to them.
Other Concerns
Outside of everything mentioned so far, it's worth noting that in addition to worries over copyright infringement or illegally acquiring PII, there're also issues some bring up like breach of contract.
After all, does the use of automated software to scrape a website violate a business's T&C? (It does if the T&C is enforceable and it specifically prohibits website scraping.)
As well, in both the U.S. and the UK website operators might try to bring a common law tort, such as trespass to chattels. An example of another law that some might try to use to prohibit scraping include the UK's Computer Misuse Act of 1990 that prohibits modification of, or access to, unauthorized computer materials. (It's worth noting that this has never been attempted in connection with web scraping.)
Closing Thoughts
Although many still see the legality of web scraping as a gray area, there are some things that are no longer in question. If the information scraped isn't protected by a login, it's legal to scrape. (Keep in mind that using that data once you've scraped it may not be legal.)
Before scraping a website, you should always check that site's T&C to ensure that you won't be in breach of contract if you do scrape it.
On the flip side, if you don't want to have your data scraped, then you need to have specific protections written into your website's T&C. Additionally, you should use a clickwrap agreement to ensure that website visitors explicitly agree to your T&C Agreement.

The first step to compliance: A Privacy Policy.
Stay compliant with our agreements, policies, and consent banners — everything you need, all in one place.





