

AI Summarize
![]()
![]()
![]()
![]()
![]()
Share
![]()
![]()
![]()
Anonymization under the EU's General Data Protection Regulation (GDPR), and de-identification under the California Consumer Protection Act (CCPA/CPRA) are both ways to protect the privacy of data subjects.
De-identification is a process that can be used in the U.S. for compliance with the CCPA (CPRA). In contrast, GDPR anonymization is used as an alternative to CCPA (CPRA) de-identification in Europe for compliance with GDPR regulations.
The two processes are comparable, but have some crucial differences in protecting personal information from disclosure by limiting access and use of identified or identifiable information.
This article will discuss both the GDPR's anonymization requirements and the CCPA/CPRA's de-identification demands. It will then go into what business owners must do to satisfy both.
(Note that the CCPA was amended by the CPRA, taking effect on January 1, 2023.)
Our Privacy Policy Generator makes it easy to create a Privacy Policy for your business. Just follow these steps:
-
At Step 1, select the Website option or App option or both.
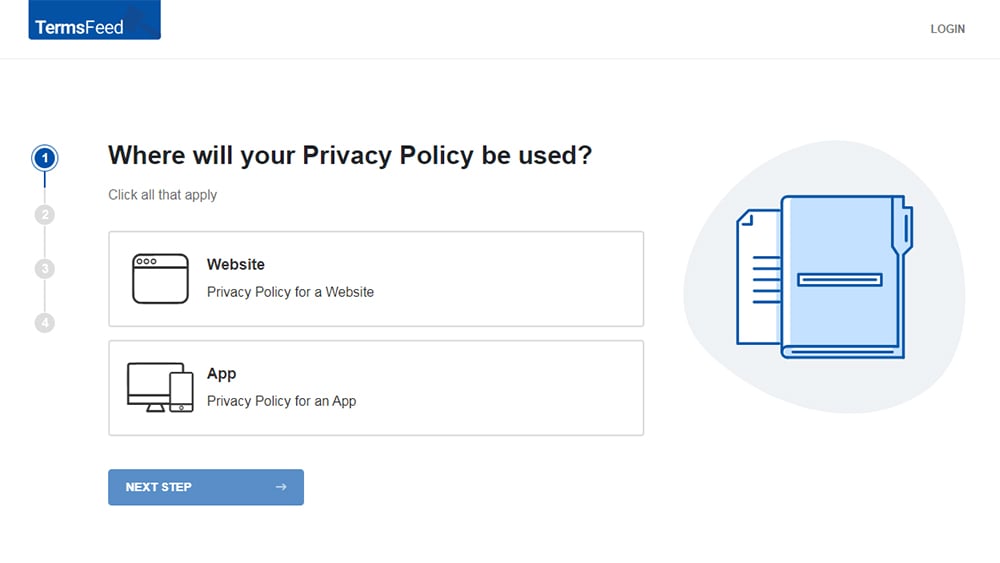
-
Answer some questions about your website or app.
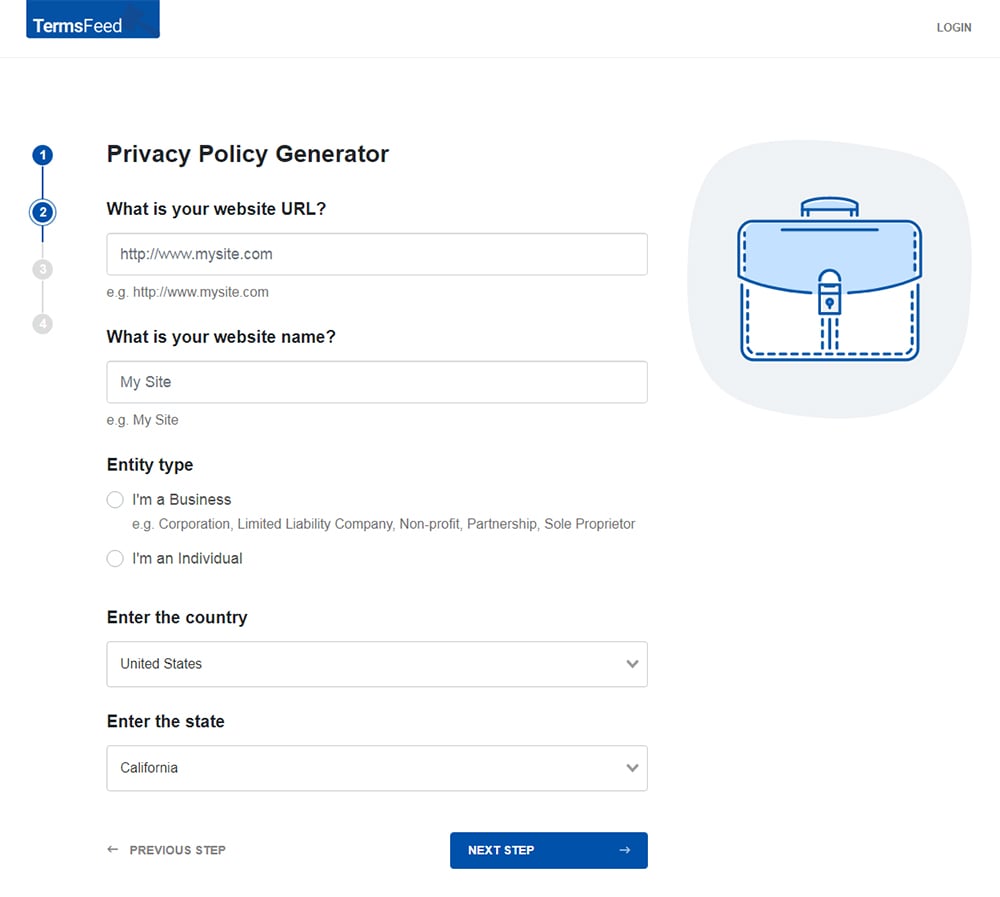
-
Answer some questions about your business.
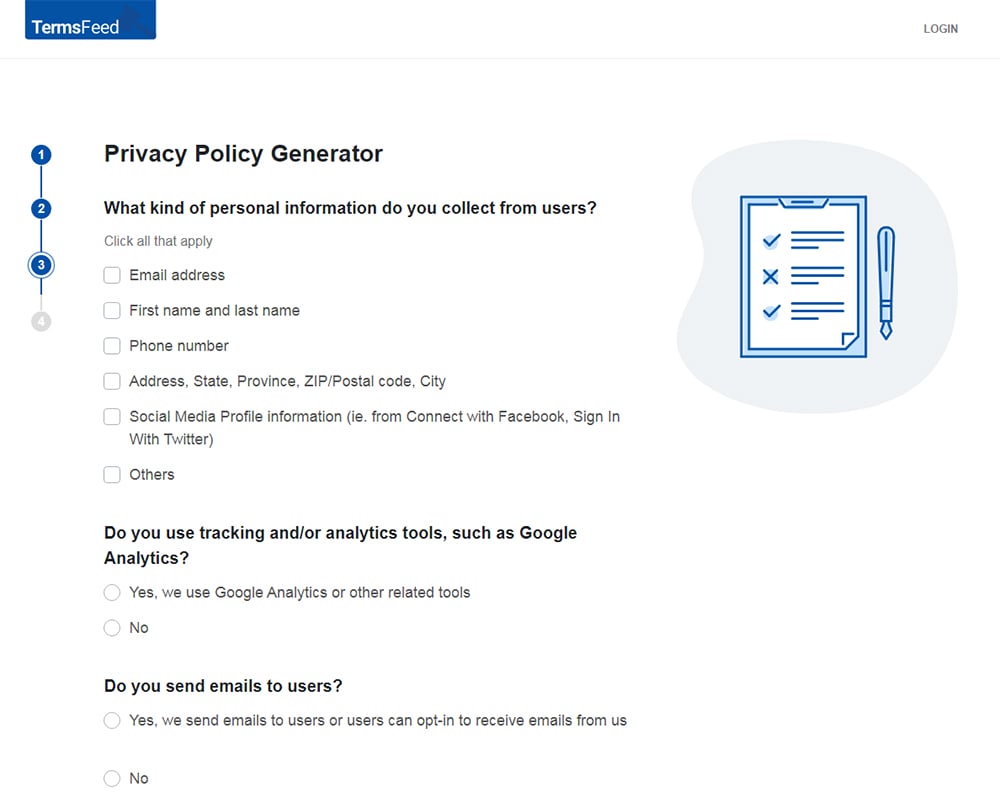
-
Enter the email address where you'd like the Privacy Policy delivered and click "Generate."
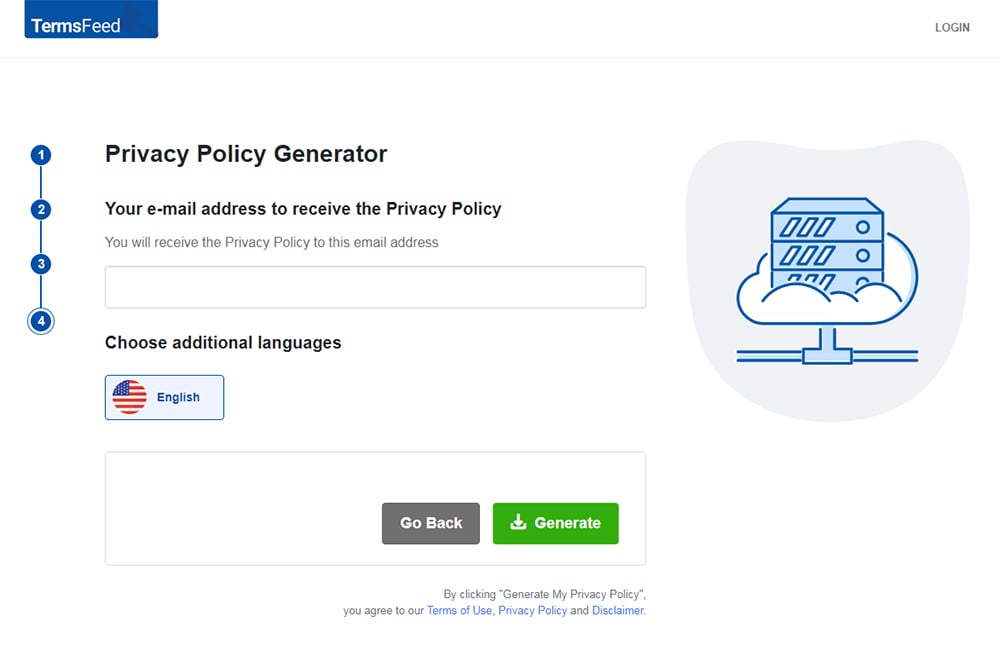
You'll be able to instantly access and download your new Privacy Policy.




- 1. What is GDPR Anonymization?
- 2. What is CCPA (CPRA) De-identification?
- 2.1. Compliantly De-Identifying Data
- 3. Why GDPR Anonymization and CCPA (CPRA) De-identification are Needed
- 4. Advantages of Anonymizing Data in Your Business
- 5. How to Comply With Anonymization and De-identification Requirements in the GDPR and CCPA (CPRA)
- 5.1. Use an Effective Anonymization Solution
- 5.2. Data Masking
- 5.3. Pseudonymization
- 5.4. Generalization
- 5.5. Data Swapping
- 5.6. Data Perturbation
- 5.7. Synthetic Data
- 6. Conduct a Motivated Intruder Test
- 7. Adopt a Governance Structure
- 8. Summary
What is GDPR Anonymization?
The GDPR's Recital 26 defines anonymous information as:
"...information which does not relate to an identified or identifiable natural person or to personal data rendered anonymous in such a manner that the data subject is not or no longer identifiable."
The process of removing indirect and direct personal identifiers that could lead to someone being identified is called anonymization.
The following kinds of information are all considered direct identifiers under the GDPR:
- Name
- Address
- Postal code
- Telephone number
- Photograph or image
- Other unique personal characteristics
Businesses and third parties can use indirect identifiers under the GDPR together with other sources of information to identify an individual. They can be (but aren't limited to) things like:
- Place of work
- Job title
- Salary
- Employment history
- Services and goods purchased by the individual
- Medical diagnoses
- Geolocation
- Device ID
Once the information has been completely anonymized, it no longer falls under the requirements of the GDPR. It, therefore, becomes data that is much easier for businesses to use.
What customers say about TermsFeed:
This really is the most incredible service that most website owners should consider using.
Easy to generate custom policies in minutes & having the peace of mind & protection these policies can offer is priceless. Will definitely recommend it to others. Thank you.
- Bluesky's review for TermsFeed. Read all our testimonials here.
With TermsFeed, you can generate:
However, some feel that anonymized data is not as valuable and is no longer useful for specific purposes. If your business operates in the EEA or EU, you should carefully consider what you'll be using data for and whether anonymization is worth your organization's time and effort.
You can find more information and guidance on anonymization techniques through the U.K.'s Information Commissioner's Office (ICO).
What is CCPA (CPRA) De-identification?
The CCPA defines "de-identified information" as:
"Data, which cannot reasonably identify, relate to, describe, be capable of being associated with, or be linked, directly or indirectly, to a particular consumer."
This means the personal identifiers have been removed with the intent that they will not be associated with a specific individual again. If a business uses de-identified information, it must take four organizational and operational steps to ensure that data is neither reidentified nor distributed.
On the other hand, the GDPR's concept of anonymization is stricter than the CCPA/CPRA's de-identification requirement since the GDPR demands that an individual's identifiable information be "irreversibly prevent[ed]" from being used.
At the same time, the CCPA (CPRA) only compels businesses to "reasonably" remove identifying data.
Another clear difference is that under the CCPA (CPRA), aggregated data also cannot "reasonably" be linked to an individual or small group, while the GDPR requires "pseudonymization," which results in a longer list of information that businesses must irreversibly prevent from being connected with specific individuals.
The CCPA (CPRA) regards information which cannot reasonably identify a specific consumer as de-identified information. The caveat is that the organization must have implemented business processes and technical safeguards that will prevent its re-identification.
Additionally, the business must also have implemented processes to prevent reidentified data from being disseminated. Finally, employees of the organization are prohibited from attempting to re-identify that information.
Compliantly De-Identifying Data
Your business must do the following to de-identify data:
- Use a de-identification method, such as masking (a process where the dataEU is depersonalized). An example of this would be changing a woman's name from "Sarah" and storing it as "S&@h"
- Evaluate the probability of re-identification. If a company doesn't remove indirect means of identification, it can be relatively simple to re-identify an individual even though their direct identifiers have already been removed. For instance, if you refer to an individual as "a 55-year-old executive" instead of "John" at a company that only has an executive team of five individuals, it would be relatively easy to identify that individual.
- Create and enforce a set of controls that ensure information is shared exclusively between parties who have a direct purpose in receiving that data. In other words, information should be shared only on a "need to know" basis, and all raw data should be considered sensitive and treated with the utmost confidentiality.
Why GDPR Anonymization and CCPA (CPRA) De-identification are Needed
Data in which individuals can be identified is extremely valuable. Yet, it can be easily misused and abused if it falls into the wrong hands.
Therefore, protecting that data through anonymization or de-identification is a must in today's world. This is even more true because data breaches are more common than ever.
Companies that do business in the European Union (EU) or European Economic Area (EEA) and the United States of America must have a process wherein data is rendered useless to information thieves if a breach occurs.
Moreover, business owners should consider that there are heavy financial penalties if a regulatory body finds that they were grossly negligent during a breach. Therefore, removing data points or adding noise to a dataset so that it cannot be associated with an individual is vital.
These methods include deletion, generalization, encryption, data masking, pseudonymization, and others. Keep in mind, however, that ways of re-identification already exist. Much anonymized data can be unraveled and decoded given the correct skillset, time, and tools.
In fact, as time goes on, anonymity and de-identification requirements under the GDPR and CCPA (CPRA) will likely have to be updated as technologies for re-identification improve.
For example, back in 2007, there was significant controversy over Google Maps' ability to identify faces from street-level images, even if Google blurred out individuals' bodies. Actions on the part of tech giants like Google are just one reason requirements for data anonymization and de-identification were written into law in the first place.
However, since then, re-identification technology has vastly improved. Many are now fearful of the effects artificial intelligence (AI) could have on the ability of some to re-identify anonymized data. Indeed, with the aid of AI, it's thought that re-identification could occur with relatively little effort.
Advantages of Anonymizing Data in Your Business
First, anonymization helps protect your business against a potential loss of trust and market share. Consumers want to know that their data is safe in your hands. By anonymizing and de-identifying it, you can assure all that your company understands and enforces its duty to secure highly sensitive, confidential information against theft and misuse.
Secondly, de-identification and anonymization can help prevent insider exploitation of data. Again, this goes to the heart of maintaining the public's trust in your organization.
You should disclose to your users via your Privacy Policy that you take steps to anonymize certain types of data while under your control.
Here's an example of a clause disclosing this, from Google's Privacy Policy:

How to Comply With Anonymization and De-identification Requirements in the GDPR and CCPA (CPRA)
Use an Effective Anonymization Solution
To prevent all parties from singling out a specific person within a dataset, inferring any information from that dataset, or linking two or more records within that set, you need an effective anonymization solution.
As suggested previously, a few of these methods are encryption, generalization, data masking, and deletion.
Below are six anonymization solutions you should be aware of and understand.
Data Masking
Data masking is the process of manipulating a dataset so that all personal identifiers are replaced with general values. These should be unique for every record, but they shouldn't have any specific significance to an individual or group within your population set.
An example will help illustrate: If you were looking at data about college students (name, gender, address, telephone number, etc.) and wanted to protect the privacy of your participants, you would replace all those personal identifiers with generic examples.
In this case:
- The student's name becomes "student."
- Their gender could be replaced by a question mark or 'm/f.'
- Any other private details are masked as well.
Pseudonymization
Pseudonymization is an approach to data protection similar to masking that replaces private identifiers with pseudonyms (a.k.a., fake names), and it's most often used in conjunction with encryption techniques like hashing, tokenizing, or masking the original content so it can't be identified by its true name.
A pseudonymized dataset might contain fields such as gender (m/f), Admissions Date (MM-DD-YYYY), Admitted Credential Level ('Undergraduate,' 'Graduate,' etc.), Admitted Degree Plan Type ('Bachelors,' 'Masters,' etc.).
If desired, a third party could create a database to match records belonging together based on overlapping attributes.
Generalization
There are many different types of generalization techniques. Generalization is the process by which personal identifiers, including names and other information that someone could use to identify a person (e.g., Social Security Number), are removed from data while still preserving its relevance for an analysis or research purpose.
It can also refer to aggregation techniques such as summarizing or averaging values in a dataset. The term anonymizer may sometimes be used specifically with reference to algorithms intended for use on large datasets where some records might contain sensitive personal information, but not all do.
Here's how Google describes its process and purpose for generalizing data in its Privacy Policy:

Data Swapping
Data swapping is a technique used to swap sensitive data, such as names and social security numbers, with pseudonyms or randomized values. They are the central components of anonymization techniques that help protect against inadvertent disclosure without sacrificing accuracy.
Data swaps can also be used for other purposes, including fraud detection, risk management prevention, compliance enforcement, and more.
For example, if your company has two databases, one containing information about customers who have recently applied for credit cards and another containing information on all employees in the organization (including salary details), you might want to use data swapping when accessing both sets of data so there's no chance an employee could inadvertently pull up their own personnel records if they were looking at customer profiles.
Data Perturbation
Data perturbation is the process of adding noise or other data to a dataset so that it can't be uniquely identified.
This way, even if your company was breached and an intruder got their hands on all the information you store about customers (names, addresses, income levels) as well as employees' salaries and phone numbers, there would still be no easy way for them to find out who anyone is.
Synthetic Data
Synthetic data is created from a range of different variables such as age, income levels, gender, and other characteristics. This can be combined with the real-world data about your customers to create combinations that don't exist in reality.
Conduct a Motivated Intruder Test
As part of the re-identification risk assessment, you should conduct a motivated intruder test. This is a type of penetration test where the attacker knows that they are not permitted to access certain areas or information.
When setting up the test, ask yourself if a motivated intruder might successfully reidentify anonymized information. For example, would it be possible for an unauthorized person to gain access to data by finding out which pieces have been anonymized and then matching those with public records?
When conducting the test, ensure that the tester (the person simulating the actions of a hacker or data thief) is someone who:
- Doesn't initially know anything about your systems but is tasked with identifying specific individuals in your database
- Is competent at using modern computers
- Has access to various public databases, libraries, and the internet
- Understands basic investigative techniques
- Is not a professional penetration tester or hacker
- Is not someone with burglary skills
The idea is to simulate a typical breach attempt by someone motivated to re-identify information, but who is not a professional in that regard.
You will need to create boundary rules around what can be accessed through your API in order to prevent others from gaining too much insight into your business. You should also perform motivated intruder tests at regular intervals (e.g., every six months) if you plan on using synthetic data rather than real-world data in training models.
Adopt a Governance Structure
Adopting a governance structure will help you ensure your organization has the appropriate policies and procedures to protect data privacy at all times, including de-identifying sensitive customer records before storing them in databases or transmitting them over networks.
To maintain awareness of any changes made as part of the anonymization process, it is advisable to assign responsibility for reviewing such changes within your business.
You may accomplish this through the following steps:
- Appoint a specific person to oversee the anonymization process
- Train your staff to ensure that they have a grasp of anonymization techniques, risk mitigation, and any specific roles they have in the process
- Develop systems to identify cases where anonymization may be challenging to implement in practice. Document your decision-making process.
- Address what your policy is in terms of disaster recovery and the actions you will take in the case of data re-identification
- Join an anonymization network or organization that regularly updates business owners on the legalities surrounding anonymization
- Explain our approach to data anonymization within your Privacy Policy and any consequences to user/consumer
- Be clear as to whether users have any choice over data anonymization or not. If they have a choice, give instructions on how they can exercise it.
- Be clear as to whether you have implemented safeguards to minimize risks associated with anonymized data production
Summary
The standard for anonymization under the GDPR is not quite the same as the standards for the CCPA/CPRA's de-identification. However, the two are remarkably similar.
As with most privacy requirements, the GDPR is more strict and demands that any information which is anonymized becomes so, irreversibly.
In contrast, the CCPA (CPRA) demands that data only be "reasonably" de-identified.
With that said, advantages of anonymizing or de-identifying data include protection against the loss of market share or trust, safeguarding against misuse by insiders as well as outside parties, and increasing compliance with standards to ensure data security.

The first step to compliance: A Privacy Policy.
Stay compliant with our agreements, policies, and consent banners — everything you need, all in one place.





